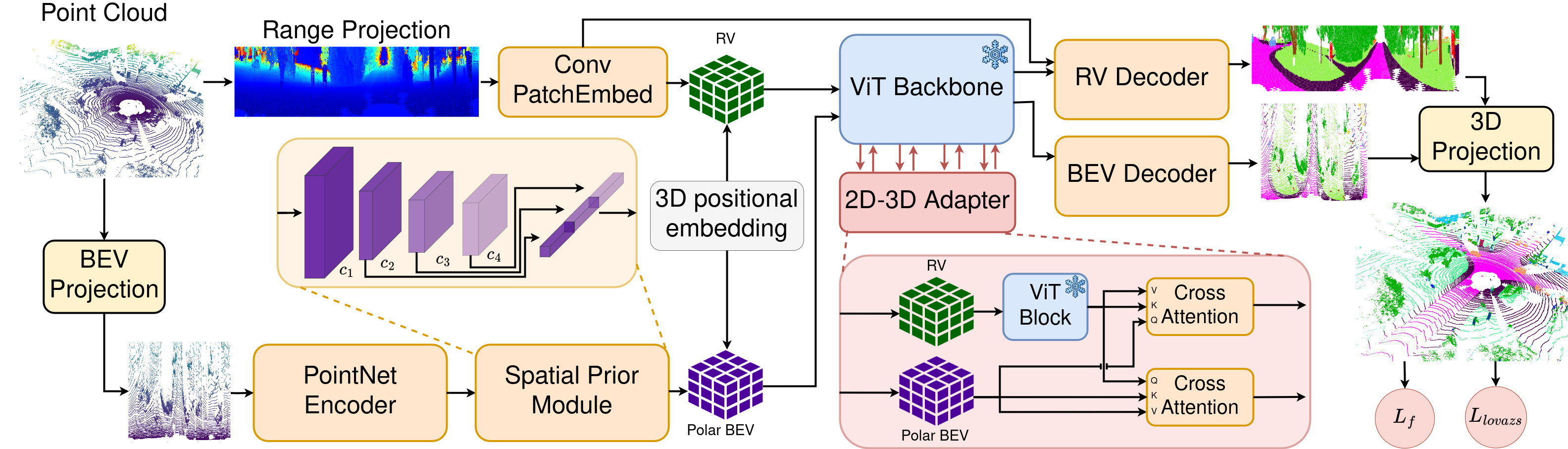
LiDAR semantic segmentation models are typically trained from random initialization as universal pre-training is hindered by the lack of large, diverse datasets. Moreover, most point cloud segmentation architectures incorporate custom network layers, limiting the transferability of advances from vision-based architectures. Inspired by recent advances in universal foundation models, we propose BALViT, a novel approach that leverages frozen vision models as amodal feature encoders for learning strong LiDAR encoders. Specifically, BALViT incorporates both range-view and bird's-eye-view LiDAR encoding mechanisms, which we combine through a novel 2D-3D adapter. While the range-view features are processed through a frozen image backbone, our bird's-eye-view branch enhances them through multiple cross-attention interactions. Thereby, we continuously improve the vision network with domain-dependent knowledge, resulting in a strong label-efficient LiDAR encoding mechanism. Extensive evaluations of BALViT on the SemanticKITTI and nuScenes benchmarks demonstrate that it outperforms state-of-the-art methods on small data regimes.


Label-Efficient LiDAR Semantic Segmentation with 2D-3D Vision Transformer Adapters
Julia Hindel, Rohit Mohan, Jelena Bratulić, Daniele Cattaneo, Thomas Brox, Abhinav Valada